题目描述(中等难度)
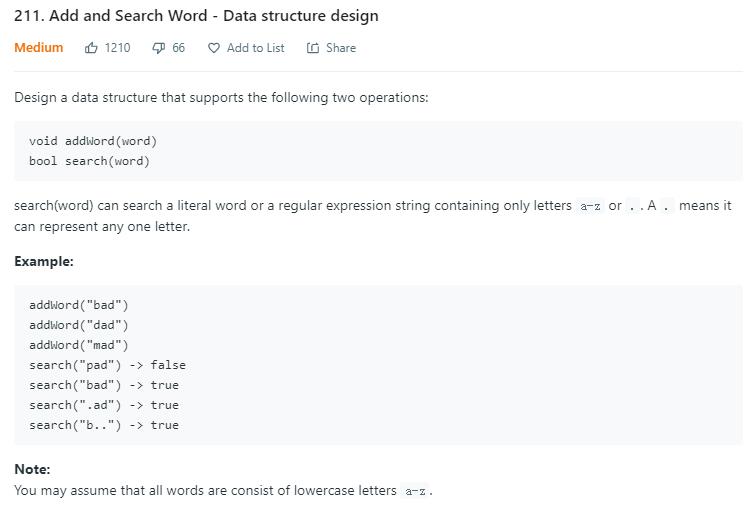
设计一个数据结构,实现 add 方法添加字符串,search 查找字符串,所查找的字符串可能含有 . ,代表任意的字符。
解法一 暴力
来个暴力的方法,用 HashSet 存入所有的字符串。当查找字符串的时候,我们首先判断 set 中是否存在,如果存在的话直接返回 true 。不存在的话,因为要查找的字符串中可能含有 . ,接下来我们需要遍历 set ,一个一个的进行匹配。
class WordDictionary {
HashSet<String> set;
/** Initialize your data structure here. */
public WordDictionary() {
set = new HashSet<>();
}
/** Adds a word into the data structure. */
public void addWord(String word) {
set.add(word);
}
/**
* Returns if the word is in the data structure. A word could contain the
* dot character '.' to represent any one letter.
*/
public boolean search(String word) {
if (set.contains(word)) {
return true;
}
for (String s : set) {
if (equal(s, word)) {
return true;
}
}
return false;
}
private boolean equal(String s, String word) {
char[] c1 = s.toCharArray();
char[] c2 = word.toCharArray();
int n1 = s.length();
int n2 = word.length();
if (n1 != n2) {
return false;
}
for (int i = 0; i < n1; i++) {
//. 代表任意字符,跳过
if (c1[i] != c2[i] && c2[i] != '.') {
return false;
}
}
return true;
}
}
当然,由于有些暴力,出现了超时。
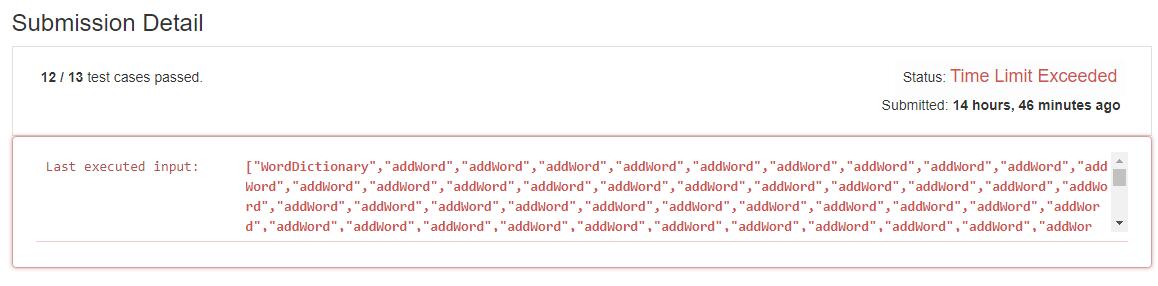
至于优化的话,我们不要将加入的字符串一股脑的放入一个 set 中,可以通过长度进行分类,将长度相同的放到一个 set 中。这样一个一个匹配的时候,规模会减小一些。
class WordDictionary {
HashMap<Integer,HashSet<String>> map;
/** Initialize your data structure here. */
public WordDictionary() {
map = new HashMap<>();
}
/** Adds a word into the data structure. */
public void addWord(String word) {
int n = word.length();
//将字符串加入对应长度的 set 中
if (map.containsKey(n)) {
HashSet<String> set = map.get(n);
set.add(word);
} else {
HashSet<String> set = new HashSet<String>();
set.add(word);
map.put(n, set);
}
}
/**
* Returns if the word is in the data structure. A word could contain the
* dot character '.' to represent any one letter.
*/
public boolean search(String word) {
HashSet<String> set = map.getOrDefault(word.length(), new HashSet<String>());
if (set.contains(word)) {
return true;
}
for (String s : set) {
if (equal(s, word)) {
return true;
}
}
return false;
}
private boolean equal(String s, String word) {
char[] c1 = s.toCharArray();
char[] c2 = word.toCharArray();
int n1 = s.length();
int n2 = word.length();
if (n1 != n2) {
return false;
}
for (int i = 0; i < n1; i++) {
if (c1[i] != c2[i] && c2[i] != '.') {
return false;
}
}
return true;
}
}
虽然上边的解法在 leetcode 中 AC 了,但其实很大程度上取决于 test cases 中所有字符串长度的分布,如果字符串长度全部集中于某个值,上边的解法的优化其实是无能为力的。
上边是按长度分类进行添加的,同样的我们还可以按照字符串的开头字母进行分类。当然,算法的速度同样也依赖于数据的分布,适用于数据分布均匀的情况。
解法二 前缀树
前几天在 208 题 刚做了前缀树,这里的话我们也可以通过前缀树进行存储,这样查找字符串就不用依赖于字符串的数量了。
代码的话在前缀树的基础上改一下就可以,大家可以先看一下 208 题。对于字符串中的 . ,我们通过递归去查找。
class WordDictionary {
class TrieNode {
TrieNode[] children;
boolean flag;
public TrieNode() {
children = new TrieNode[26];
flag = false;
for (int i = 0; i < 26; i++) {
children[i] = null;
}
}
}
TrieNode root;
/** Initialize your data structure here. */
public WordDictionary() {
root = new TrieNode();
}
/** Adds a word into the data structure. */
public void addWord(String word) {
char[] array = word.toCharArray();
TrieNode cur = root;
for (int i = 0; i < array.length; i++) {
// 当前孩子是否存在
if (cur.children[array[i] - 'a'] == null) {
cur.children[array[i] - 'a'] = new TrieNode();
}
cur = cur.children[array[i] - 'a'];
}
// 当前节点代表结束
cur.flag = true;
}
/**
* Returns if the word is in the data structure. A word could contain the
* dot character '.' to represent any one letter.
*/
public boolean search(String word) {
return searchHelp(word, root);
}
private boolean searchHelp(String word, TrieNode root) {
char[] array = word.toCharArray();
TrieNode cur = root;
for (int i = 0; i < array.length; i++) {
// 对于 . , 递归的判断所有不为空的孩子
if(array[i] == '.'){
for(int j = 0;j < 26; j++){
if(cur.children[j] != null){
if(searchHelp(word.substring(i + 1),cur.children[j])){
return true;
}
}
}
return false;
}
// 不含有当前节点
if (cur.children[array[i] - 'a'] == null) {
return false;
}
cur = cur.children[array[i] - 'a'];
}
// 当前节点是否为是某个单词的结束
return cur.flag;
}
}
解法三
再分享一个 leetcode 上边的大神 @StefanPochmann 的一个想法,直接利用正则表达式。
我就不细讲了,直接看代码吧,很简洁。
import re
class WordDictionary:
def __init__(self):
self.words = '#'
def addWord(self, word):
self.words += word + '#'
def search(self, word):
return bool(re.search('#' + word + '#', self.words))
我用 java 改写了一下。
import java.util.regex.*;
class WordDictionary {
StringBuilder sb;
public WordDictionary() {
sb = new StringBuilder();
sb.append('#');
}
public void addWord(String word) {
sb.append(word);
sb.append('#');
}
public boolean search(String word) {
Pattern p = Pattern.compile('#' + word + '#');
Matcher m = p.matcher(sb.toString());
return m.find();
}
}
不过遗憾的是,java 在 leetcode 上这个解法会超时,python 没什么问题。当然优化的话,我们可以再像解法一那样对字符串进行分类,这里就不再写了。
上边的解法的关键就是,用 # 分割不同单词,以及查找的时候查找 # + word + # ,很妙。
总
解法一是直觉上的解法,分类的思想也经常用到。解法二的话,需要数据结构的积累,刚好前几题实现了前缀树,空间换时间,这里也就直接想到了。解法三的话,大概只有大神能想到了,一种完全不同的视角,很棒。