题目描述(中等难度)
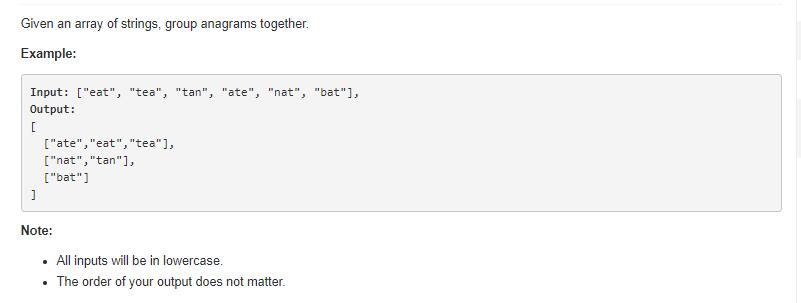
给定多个字符串,然后把它们分类。只要字符串所包含的字符完全一样就算作一类,不考虑顺序。
解法一
最通用的一种解法,对于每个字符串,比较它们的每个字符出现的个数是否相等,相等的话就把它们放在一个 list 中去,作为一个类别。最外层写一个 for 循环然后一一比较就可以,还可以用一个等大的布尔型数组来记录当前字符串是否已经加入的了 list 。比较两个字符串的字符出现的次数可以用一个 HashMap,具体看代码吧。
public List<List<String>> groupAnagrams(String[] strs) {
List<List<String>> ans = new ArrayList<>();
boolean[] used = new boolean[strs.length];
for (int i = 0; i < strs.length; i++) {
List<String> temp = null;
if (!used[i]) {
temp = new ArrayList<String>();
temp.add(strs[i]);
//两两比较判断字符串是否符合
for (int j = i + 1; j < strs.length; j++) {
if (equals(strs[i], strs[j])) {
used[j] = true;
temp.add(strs[j]);
}
}
}
if (temp != null) {
ans.add(temp);
}
}
return ans;
}
private boolean equals(String string1, String string2) {
Map<Character, Integer> hash = new HashMap<>();
//记录第一个字符串每个字符出现的次数,进行累加
for (int i = 0; i < string1.length(); i++) {
if (hash.containsKey(string1.charAt(i))) {
hash.put(string1.charAt(i), hash.get(string1.charAt(i)) + 1);
} else {
hash.put(string1.charAt(i), 1);
}
}
//记录第一个字符串每个字符出现的次数,将之前的每次减 1
for (int i = 0; i < string2.length(); i++) {
if (hash.containsKey(string2.charAt(i))) {
hash.put(string2.charAt(i), hash.get(string2.charAt(i)) - 1);
} else {
return false;
}
}
//判断每个字符的次数是不是 0 ,不是的话直接返回 false
Set<Character> set = hash.keySet();
for (char c : set) {
if (hash.get(c) != 0) {
return false;
}
}
return true;
}
时间复杂度:两层 for 循环,再加上比较字符串,如果字符串最长为 K,总的时间复杂度就是 O(n²K)。
空间复杂度:O(NK),用来存储结果。
解法一算是比较通用的解法,不管字符串里边是大写字母,小写字母,数字,都可以用这个算法解决。这道题的话,题目告诉我们字符串中只有小写字母,针对这个限制,我们可以再用一些针对性强的算法。
下边的算法本质是,我们只要把一类的字符串用某一种方法唯一的映射到同一个位置就可以。
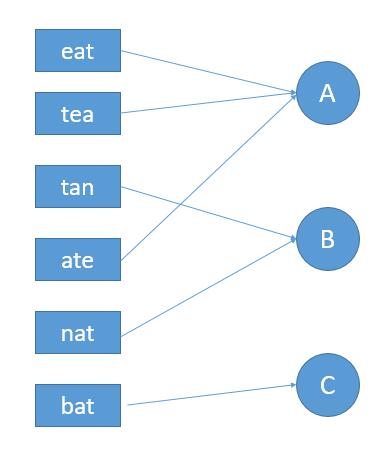
解法二
参考官方给的解法。
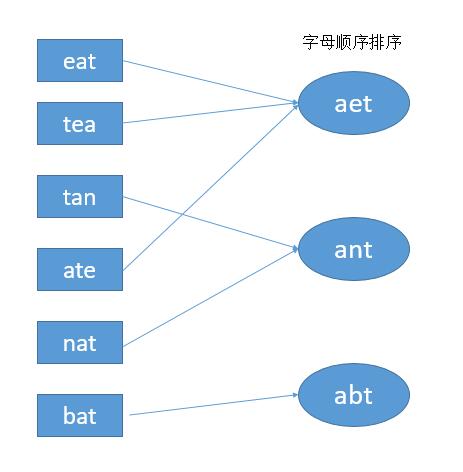
我们将每个字符串按照字母顺序排序,这样的话就可以把 eat,tea,ate 都映射到 aet。其他的类似。
public List<List<String>> groupAnagrams(String[] strs) {
HashMap<String, List<String>> hash = new HashMap<>();
for (int i = 0; i < strs.length; i++) {
char[] s_arr = strs[i].toCharArray();
//排序
Arrays.sort(s_arr);
//映射到 key
String key = String.valueOf(s_arr);
//添加到对应的类中
if (hash.containsKey(key)) {
hash.get(key).add(strs[i]);
} else {
List<String> temp = new ArrayList<String>();
temp.add(strs[i]);
hash.put(key, temp);
}
}
return new ArrayList<List<String>>(hash.values());
}
时间复杂度:排序的话算作 O(K log(K)),最外层的 for 循环,所以就是 O(n K log(K))。
空间复杂度:O(NK),用来存储结果。
解法三
算术基本定理,又称为正整数的唯一分解定理,即:每个大于1的自然数,要么本身就是质数,要么可以写为2个以上的质数的积,而且这些质因子按大小排列之后,写法仅有一种方式。
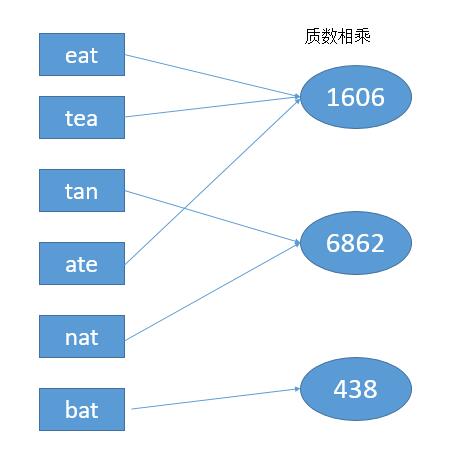
利用这个,我们把每个字符串都映射到一个正数上。
用一个数组存储质数 prime = {2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97, 101, 103}。
然后每个字符串的字符减去 ' a ' ,然后取到 prime 中对应的质数。把它们累乘。
例如 abc ,就对应 'a' - 'a', 'b' - 'a', 'c' - 'a',即 0, 1, 2,也就是对应素数 2 3 5,然后相乘 2 3 5 = 30,就把 "abc" 映射到了 30。
public List<List<String>> groupAnagrams(String[] strs) {
HashMap<Integer, List<String>> hash = new HashMap<>();
//每个字母对应一个质数
int[] prime = { 2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97, 101, 103 };
for (int i = 0; i < strs.length; i++) {
int key = 1;
//累乘得到 key
for (int j = 0; j < strs[i].length(); j++) {
key *= prime[strs[i].charAt(j) - 'a'];
}
if (hash.containsKey(key)) {
hash.get(key).add(strs[i]);
} else {
List<String> temp = new ArrayList<String>();
temp.add(strs[i]);
hash.put(key, temp);
}
}
return new ArrayList<List<String>>(hash.values());
}
时间复杂度:O(n * K),K 是字符串的最长长度。
空间复杂度:O(NK),用来存储结果。
这个解法时间复杂度,较解法二有提升,但是有一定的局限性,因为求 key 的时候用的是累乘,可能会造成溢出,超出 int 所能表示的数字。
解法四
参考这里,记录字符串的每个字符出现的次数从而完成映射。因为有 26 个字母,不好解释,我们假设只有 5 个字母,来看一下怎么完成映射。
首先初始化 key = "0#0#0#0#0#",数字分别代表 abcde 出现的次数,# 用来分割。
这样的话,"abb" 就映射到了 "1#2#0#0#0"。
"cdc" 就映射到了 "0#0#2#1#0"。
"dcc" 就映射到了 "0#0#2#1#0"。
public List<List<String>> groupAnagrams(String[] strs) {
HashMap<String, List<String>> hash = new HashMap<>();
for (int i = 0; i < strs.length; i++) {
int[] num = new int[26];
//记录每个字符的次数
for (int j = 0; j < strs[i].length(); j++) {
num[strs[i].charAt(j) - 'a']++;
}
//转成 0#2#2# 类似的形式
String key = "";
for (int j = 0; j < num.length; j++) {
key = key + num[j] + '#';
}
if (hash.containsKey(key)) {
hash.get(key).add(strs[i]);
} else {
List<String> temp = new ArrayList<String>();
temp.add(strs[i]);
hash.put(key, temp);
}
}
return new ArrayList<List<String>>(hash.values());
}
时间复杂度: O(nK)。
空间复杂度:O(NK),用来存储结果。
总
利用 HashMap 去记录字符的次数之前也有遇到过,很常用。解法三中利用质数相乘,是真的太强了。