题目描述(中等难度)
求 H 指数,H 指数等于 n,代表该作者所发表的所有论文中至少有 n 篇论文的被引用次数大于等于 n。
解法一
第一次看到这个概念比较难理解,看一下 维基百科) 的定义。
H指数的计算基于其研究者的论文数量及其论文被引用的次数。赫希认为:一个人在其所有学术文章中有N篇论文分别被引用了至少N次,他的H指数就是N。如美国耶鲁大学免疫学家理查德·弗来沃发表的900篇文章中,有107篇被引用了107次以上,他的H指数是107。
可以按照如下方法确定某人的H指数:
- 将其发表的所有SCI论文按被引次数从高到低排序;
- 从前往后查找排序后的列表,直到某篇论文的序号大于该论文被引次数。所得序号减一即为H指数。
我们先按照上边提供的解法写一下代码。
public int hIndex(int[] citations) {
Arrays.sort(citations); // 默认的是从小到大排序,所以后边要倒着遍历
int n = 1; // 论文序号
//倒着遍历就是从大到小遍历了
for (int i = citations.length - 1; i >= 0; i--) {
// 论文序号大于该论文的被引次数
if (n > citations[i]) {
break;
}
n++;
}
// 所得序号减一即为 H 指数。
return n - 1;
}
我们结合下图理解一下上边的算法,把 [3,0,6,1,5] 从大到小排序,画到图中。
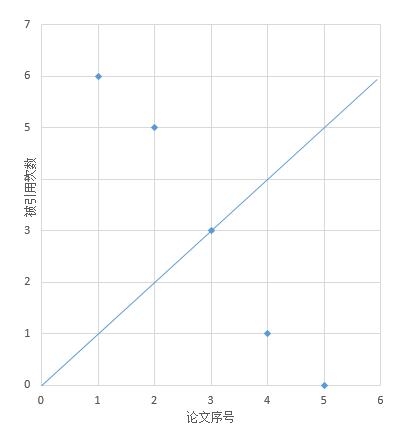
上边的 H-Index 是 3,在图中表现的话就是有 3 个点在直线上方(包括在直线上),其他点在直线下方。
我们从大到小排序后,其实就是依次判断点是否在直线上方(包括在直线上),如果出现了点在直线下方,那么前一个点的横坐标就是我们要找的 H-Index。
我们也可以从小到大遍历,结合下图。
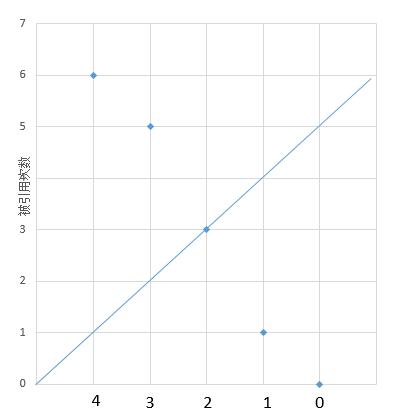
我们从 0 开始遍历,依次判断点是否在直线下方,如果出现了点在直线上方(包括在直线上),那么当前点的垂线与直线交点的纵坐标就是 H-Index 了。
点的垂线与直线交点的纵坐标的求法是 n - i,n 是数组长度,i 是数组下标。
这就是 这里-time-with-sort-O(n)-time-with-O(n)-space) 代码的理解了。
public int hIndex(int[] citations) {
Arrays.sort(citations);
int n = citations.length;
for (int i = 0; i < n; i++) {
// 点在直线上方
if (citations[i] >= n - i) {
return n - i;
}
}
return 0;
}
解法二
参考 这里-solution-with-detail-explanation) ,换一种思路理解。
首先如果数组的长度是 n,那么 H-Index 最大也就是 n。
我们先判断 H-Index 是不是 n,如果被引次数大于等于 n 的论文数大于等于 n,那么 H-Index 就是 n。
否则的话判断 H-Index 是不是 n - 1,如果被引次数大于等于 n - 1 的论文数大于等于 n - 1,那么 H-Index 就是 n - 1。
否则的话判断 H-Index 是不是 n - 2,如果被引次数大于等于 n - 2 的论文数大于等于 n - 2,那么 H-Index 就是 n - 2。
... ...
否则的话判断 H-Index 是不是 1,如果被引次数大于等于 1 的论文数大于等于 1,那么 H-Index 就是 1。
否则的话判断 H-Index 是不是 0,如果被引次数大于等于 0 的论文数大于等于 0,那么 H-Index 就是 0。
接下来的话有用到 计数排序 的思想。
上边的算法中,我们每次想要知道「被引次数大于等于 N 的论文数」, N = n, n - 1, n - 2 ... 0 。
如果我们知道了被引次数等于 0 的论文数,被引次数等于 1 的论文数,被引次数等于 2 的论文数 ... 被引次数等于 n - 1 的论文数,那么通过累加,被引次数大于等于 0 到被引次数大于等于 n - 1 的论文数也就知道了。
因为我们只关心被引次数大于等于 n 的论文数,所以被引次数等于 n 的论文数,所以被引次数等于 n + 1 的论文数,所以被引次数等于 n + 2 的论文数... 都不是我们关心的,我们只需要记录被引次数大于等于 n 的论文数。
综上,我们需要一个额外空间,分别存储被引次数等于 0 的论文数,被引次数等于 1 的论文数,被引次数等于 2 的论文数 ... 被引次数等于 n - 1 的论文数以及被引次数大于等于 n 的论文数。
然后回到算法最开始,依次判断被引次数大于等于 N 的论文数是否大于等于 N 即可, N = n, n - 1, n - 2 ... 0 。
public int hIndex(int[] citations) {
int n = citations.length;
int[] buckets = new int[n+1];
//计数
for(int c : citations) {
if(c >= n) {
buckets[n]++;
} else {
buckets[c]++;
}
}
int count = 0;
//依次判断被引次数大于等于 N 的论文数是否大于等于 N
for(int i = n; i >= 0; i--) {
count += buckets[i];
if(count >= i) {
return i;
}
}
return 0;
}
参考 这里-time-O(1)space-solution),我们还能进一步的优化,我们可以利用原有的数组 citations 计数,不再开辟新的空间 buckets。
用原有数组计数的话,假设 citations[0] = 3,那么我们应该将 citations[3] = 1。但如果我们遍历到了 citations[3] 的时候,此时它代表的是被引用次数等于 3 的论文数,而不是当前论文的被引用次数。
所以我们需要区分当前数字是在计数还是表示论文的被引用次数。
有一个 trick,注意到论文被引用次数都是非负数,所以我们可以用负数计数。用 -1 代表 0, -2 代表 1, -3 代表 2... 以此类推。这样的话,从负数到它的原本含义的映射就是「先取相反数,然后再减一」。
如果当前是 -4 ,那么它代表 -(-4) - 1 = 3。
取相反数,在 补码 中讨论过,可以通过取反加一替代,代入原来的映射 「先取相反数,然后再减一」,就是 「先取反加一,然后再减一」,所以就是 「取反」即可。
还有个问题需要解决。
假设 citations[0] = 3,那么我们应该将 citations[3] = -2,如果直接这样做的话,citations[3] 之前的数就被替代了。所以替代前,我们还需要将 citations[3] 存起来,然后重复这步。
还有一些细节,可以结合代码看,文字有些难描述。
因为我们数组大小是 n,那么只能统计 0 的 n - 1 的情况,还需要一个变量单独记录被引用数大于等于 n 的论文数。
public int hIndex(int[] citations) {
int n = citations.length;
int N = 0; // 记录引用数大于等于 n 的论文数
for (int i = 0; i < n; i++) {
int count = citations[i];
//已经记录过这个数
if (count < 0) {
continue;
}
//初始化为 0
citations[i] = -1; // -1 -> 0
//大于等于 n 的情况,用 N 统计
if (count >= n) {
N++;
continue;
}
//当前值之前是否被统计过
while (citations[count] >= 0) {
//保存当前论文被引用次数
int temp = citations[count];
//统计当前数,初始化为 1
citations[count] = -2; // -2 -> 1
count = temp;
//大于等于 n 的情况
if (count >= n) {
N++;
break;
}
}
//当前值之前已经被统计过,在原来的基础上减一(也就是计数加 1)
if (count < n && citations[count] < 0) {
citations[count]--;
}
}
// 全部论文引用数大于等于 n
if (N == n) {
return n;
}
int count = N;
for (int i = n - 1; i >= 0; i--) {
count = count + (~citations[i]);
if (count >= i) {
return i;
}
}
return 0;
}
总
这道题的话,如果知道定义的话很好写。然后解法二利用原有空间的思想进行优化也经常用到。