题目描述(中等难度)
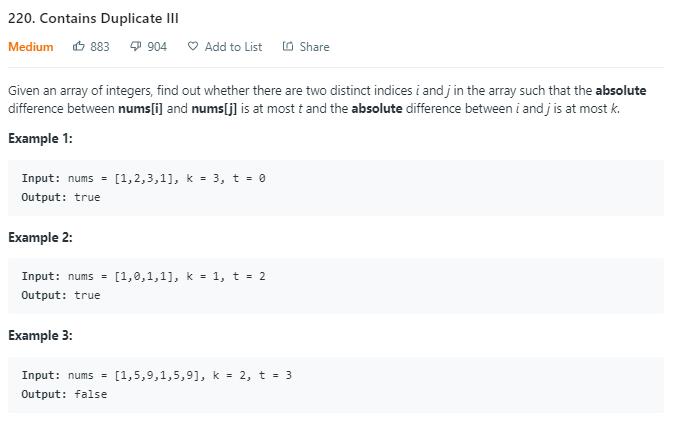
判断是否存在两个数,下标之间相差不超过 k,并且两数相差不超过 t。
先做一下 219. Contains Duplicate II ,再做这个题可能更有感觉。
解法一 暴力
两层循环,判断当前数字和下标相距它 k 内的数是否存在数值相差不超过 t 的。
public boolean containsNearbyAlmostDuplicate(int[] nums, int k, int t) {
int n = nums.length;
for (int i = 0; i < n; i++) {
for (int j = 1; j <= k; j++) {
if (i + j >= n) {
break;
}
if (Math.abs(nums[i] - nums[i + j]) <= t) {
return true;
}
}
}
return false;
}
上边的看似没有什么问题,但对于一些数相减可能会产生溢出,比如 Integer.MAX_VALUE - (-2) 就会产生溢出了,一些溢出可能导致我们最终的结果出问题。关于为什么产生溢出可以参考 趣谈补码。
最直接的解决方案,也是最偷懒的方案,题目中给我们的数据是 int,我们强制转为 long 进行运算,就不会出错了。
public boolean containsNearbyAlmostDuplicate(int[] nums, int k, int t) {
int n = nums.length;
for (int i = 0; i < n; i++) {
for (int j = 1; j <= k; j++) {
if (i + j >= n) {
break;
}
if (Math.abs((long) nums[i] - nums[i + j]) <= t) {
return true;
}
}
}
return false;
}
题目到这里已经解决了,我们再多思考一下,不借助 long 可以做吗?
两数相减然后取绝对值出现了溢出,也就意味着绝对值的结果大于了 Integer.MAX_VALUE,而 t <= Integer.MAX_VALUE,也就意味着此时两数相差不满足小于等于 t 的条件。
换句话讲,如果两数相减取绝对值产生了溢出,那么此时结果一定是大于 t 的,可以直接跳过。
因此,接下来只需要解决怎么判断是否产生溢出即可。
两数相减有四种情况。
正数减正数,不会产生溢出。
正数减负数,结果一定是正数,如果此时结果是负数,说明出现了溢出。
负数减正数,结果一定是负数,如果此时结果是正数,说明出现了溢出。这里还有一种特殊情况需要考虑,我们知道负数比正数多一个。最小的负数是
-2147483648,最大的正数是2147483647。如果我们计算
-2147483647 - 1 = -2147483648,虽然结果没有溢出,但如果取绝对值,由于正数不能表示2147483648,所以这种情况也需要看成溢出。负数减负数,不会产生溢出。
代码的话,考虑可能产生溢出的两种情况即可。
public boolean containsNearbyAlmostDuplicate(int[] nums, int k, int t) {
int n = nums.length;
for (int i = 0; i < n; i++) {
for (int j = 1; j <= k; j++) {
if (i + j >= n) {
break;
}
int sub = nums[i] - nums[i + j];
//正数减负数, 0 算作正数,因为 0 - (-2147483648) 会出现溢出
if (nums[i] >= 0 && nums[i + j] < 0) {
if (sub < 0) {
continue;
}
}
//负数减正数
if (nums[i] < 0 && nums[i + j] >= 0) {
if (sub > 0 || sub == Integer.MIN_VALUE) {
continue;
}
}
if (Math.abs(sub) <= t) {
return true;
}
}
}
return false;
}
但是这个解法竟然超时了,百思不得其解,,,大家谁知道可以告诉我为什么。
解法二
考虑下算法的优化,受 219 题 的启发,利用一个滑动窗口,我们只考虑当前数前边的窗口内情况。那么问题来了,比较窗口内的什么呢?
如果我们知道窗口内的最大值和最小值,那就可以优化一下算法,举个例子。
k = 3, t = 2, 窗口内 3 个数,当前考虑 x
2 6 3 x 5
^ ^
窗口内的数是 2 6 3,最大数是 max, 最小数是 min
我们把 x 和最大数和最小数比较
如果 x >= max, 那么如果 x 和 max 的差大于了 t, 那么和窗口内的其他数的差肯定都大于 t, 也就不需要判断了
如果 x <= min, 那么如果 min 和 x 的差大于了 t, 那么窗口内的其他数和它的差肯定都大于 t, 也就不需要判断了
如果 min < x < max, 这样的话就只能按照解法一暴力的方式,一个一个判断了
如果没有找到符合条件的解, 那么就将窗口中的第一个数删除, 将 x 加入窗口后继续判断
2 6 3 x 5
^ ^
继续考虑 5 和窗口内最大数和最小数的情况。
上边的分析,我们需要得到最大数和最小数,以及从窗口内删除数。受 218 题 启发,我们可以用两个 TreeMap ,这样得到最大数或者最小数时间复杂度是 O(log(n)),以及删除一个数字也是 O(log(n)) 。
public boolean containsNearbyAlmostDuplicate(int[] nums, int k, int t) {
//为了得到窗口内的最大数
TreeMap<Integer, Integer> maxTreeMap = new TreeMap<>(new Comparator<Integer>() {
@Override
public int compare(Integer i1, Integer i2) {
return i2 - i1;
}
});
//为了得到窗口内的最小数
TreeMap<Integer, Integer> minTreeMap = new TreeMap<>();
int n = nums.length;
if (n == 0) {
return false;
}
maxTreeMap.put(nums[0], 1);
minTreeMap.put(nums[0], 1);
for (int i = 1; i < n; i++) {
//将窗口内的第一个数删除
if (i > k) {
remove(maxTreeMap, nums[i - k - 1]);
remove(minTreeMap, nums[i - k - 1]);
}
if (maxTreeMap.size() == 0) {
continue;
}
long max = maxTreeMap.firstKey();
long min = minTreeMap.firstKey();
//和最大数以及最小数进行比较
if (nums[i] >= max) {
if (nums[i] - max <= t) {
return true;
}
} else if (nums[i] <= min) {
if (min - nums[i] <= t) {
return true;
}
} else {
for (int j = 1; j <= k; j++) {
if (i - j < 0) {
break;
}
if (Math.abs((long) nums[i] - nums[i - j]) <= t) {
return true;
}
}
}
//当前数加入窗口
add(maxTreeMap, nums[i]);
add(minTreeMap, nums[i]);
}
return false;
}
private void add(TreeMap<Integer, Integer> treeMap, int num) {
// TODO Auto-generated method stub
Integer v = treeMap.get(num);
if (v == null) {
treeMap.put(num, 1);
} else {
treeMap.put(num, v + 1);
}
}
private void remove(TreeMap<Integer, Integer> treeMap, int num) {
// TODO Auto-generated method stub
Integer v = treeMap.get(num);
if (v == 1) {
treeMap.remove(num);
} else {
treeMap.put(num, v - 1);
}
}
遗憾的是,对于 leetcode 的 test cases,这个解法并没有带来时间上的提升,时间甚至比解法一的暴力还慢。在中国站返回了超时错误,美国站可以 AC 。
解法三 set
参考 这里-with-simple-explanation.) 。
这个方法的前提是对 TreeSet 这个数据结构要了解。其中有一个方法 public E ceiling(E e) ,返回 treeSet 中大于等于 e 的元素中最小的元素,如果没有大于等于 e 的元素就返回 null。
还有一个对应的方法,public E floor(E e),返回 treeSet 中小于等于 e 的元素中最大的元素,如果没有小于等于 e 的元素就返回 null。
并且两个方法的时间复杂度都是 O(log(n))。
知道了这个就好说了,我们依旧是解法二那样的滑动窗口,举个例子。
k = 3, t = 2, 窗口内 3 个数用 TreeSet 存储, 当前考虑 x
2 6 3 x 5
^ ^
此时我们去寻找窗口中是否存在 x - t ~ x + t 的元素。
如果我们调用 ceilling(x - t) 返回了 c,c 是窗口内大于等于 x - t 中最小的数。
只要 c 不大于 x + t, 那么 c 一定是我们要找的了。否则的话,窗口就继续右移。
代码的话,由于溢出的问题,运算的时候我们直接用 long 强转。
public boolean containsNearbyAlmostDuplicate(int[] nums, int k, int t) {
TreeSet<Long> set = new TreeSet<>();
int n = nums.length;
for (int i = 0; i < n; i++) {
if (i > k) {
set.remove((long)nums[i - k - 1]);
}
Long low = set.ceiling((long) nums[i] - t);
//是否找到了符合条件的数
if (low != null && low <= (long)nums[i] + t) {
return true;
}
set.add((long) nums[i]);
}
return false;
}
解法四 map
参考 这里-time-O(n)-space-using-buckets)。
运用到了桶排序的思想,在 164 题 也使用过桶排序的思想。
首先还是滑动窗口的思想,一个窗口一个窗口考虑。
不同之处在于,我们把窗口内的数字存在不同编号的桶中。每个桶内存的数字范围是 t + 1 个数,这样做的好处是,桶内任意两个数之间的差一定是小于等于 t 的。
t = 2, 每个桶内的数字范围如下
编号 ... -2 -1 0 1 ...
------- ------- ------- -------
桶内数字范围 | -6 ~ -4 | | -3 ~ -1 | | 0 ~ 2 | | 3 ~ 5 |
------- ------- ------- -------
有了上边的桶,再结合滑动窗口就简单多了,同样的举个例子。
k = 3, t = 2, 窗口内 3 个数用上边的桶存储, 当前考虑 x
2 6 3 x 5
^ ^
桶中的情况
0 1 2
------- ------- -------
| 2 | | 3 | | 6 |
------- ------- -------
接下来我们只需要算出来 x 在哪个桶中。
如果 x 所在桶已经有数字了,那就说明存在和 x 相差小于等于 t 的数。
如果 x 所在桶没有数字,因为与 x 所在桶不相邻的桶中的数字与 x 的差一定大于 t,所以只需要考虑与 x 所在桶相邻的两个桶中的数字与 x的差是否小于等于 t。
如果没有找到和 x 相差小于等于 t 的数, 那么窗口右移。从桶中将窗口中第一个数删除, 并且将 x 加入桶中
接下来需要解决怎么求出一个数所在桶的编号。
//w 表示桶中的存储数字范围的个数
private long getId(long num, long w) {
if (num >= 0) {
return num / w;
} else {
//num 加 1, 把负数移动到从 0 开始, 这样算出来标号最小是 0, 已经用过了, 所以要再减 1
return (num + 1) / w - 1;
}
}
「桶」放到代码中我们要什么数据结构存储呢?我们注意到,桶中其实最多就只会有一个数字(如果有两个数字,说明我们已经找到了相差小于等于 t 的数,直接结束)。所以我们完全可以用一个 map ,key 表示桶编号,value 表示桶中当前的数字。
同样的,为了防止溢出,所有数字我们都用成了 long。
public boolean containsNearbyAlmostDuplicate(int[] nums, int k, int t) {
if (t < 0) {
return false;
}
HashMap<Long, Long> map = new HashMap<>();
int n = nums.length;
long w = t + 1; // 一个桶里边数字范围的个数是 t + 1
for (int i = 0; i < n; i++) {
//删除窗口中第一个数字
if (i > k) {
map.remove(getId(nums[i - k - 1], w));
}
//得到当前数的桶编号
long id = getId(nums[i], w);
if (map.containsKey(id)) {
return true;
}
if (map.containsKey(id + 1) && map.get(id + 1) - nums[i] < w) {
return true;
}
if (map.containsKey(id - 1) && nums[i] - map.get(id - 1) < w) {
return true;
}
map.put(id, (long) nums[i]);
}
return false;
}
private long getId(long num, long w) {
if (num >= 0) {
return num / w;
} else {
return (num + 1) / w - 1;
}
}
总
解法一暴力比较常规,解法二我应该是在潜意识中受到 164 题 的启发,用到了最大值和最小值,但对当前题并没有起到决定性的优化作用。
解法三的话,知道 treeSet 中 ceiling 方法很关键。并且思想也很棒,我们并没有去判断窗口中的数是否满足和当前数相差小于等于 t。而是反过来,去寻找满足条件的数字在窗口中是否存在。这种思维的逆转,在解题中也经常用到。
解法四的话,通过对数字的映射,从而将一部分数映射到一个 id ,进而通过 map 解决问题,很厉害。
后三种方法其实都是和滑动窗口有关,通过滑动窗口,我们保证了两个数字的下标一定是小于等于 k 的。