题目描述(简单难度)
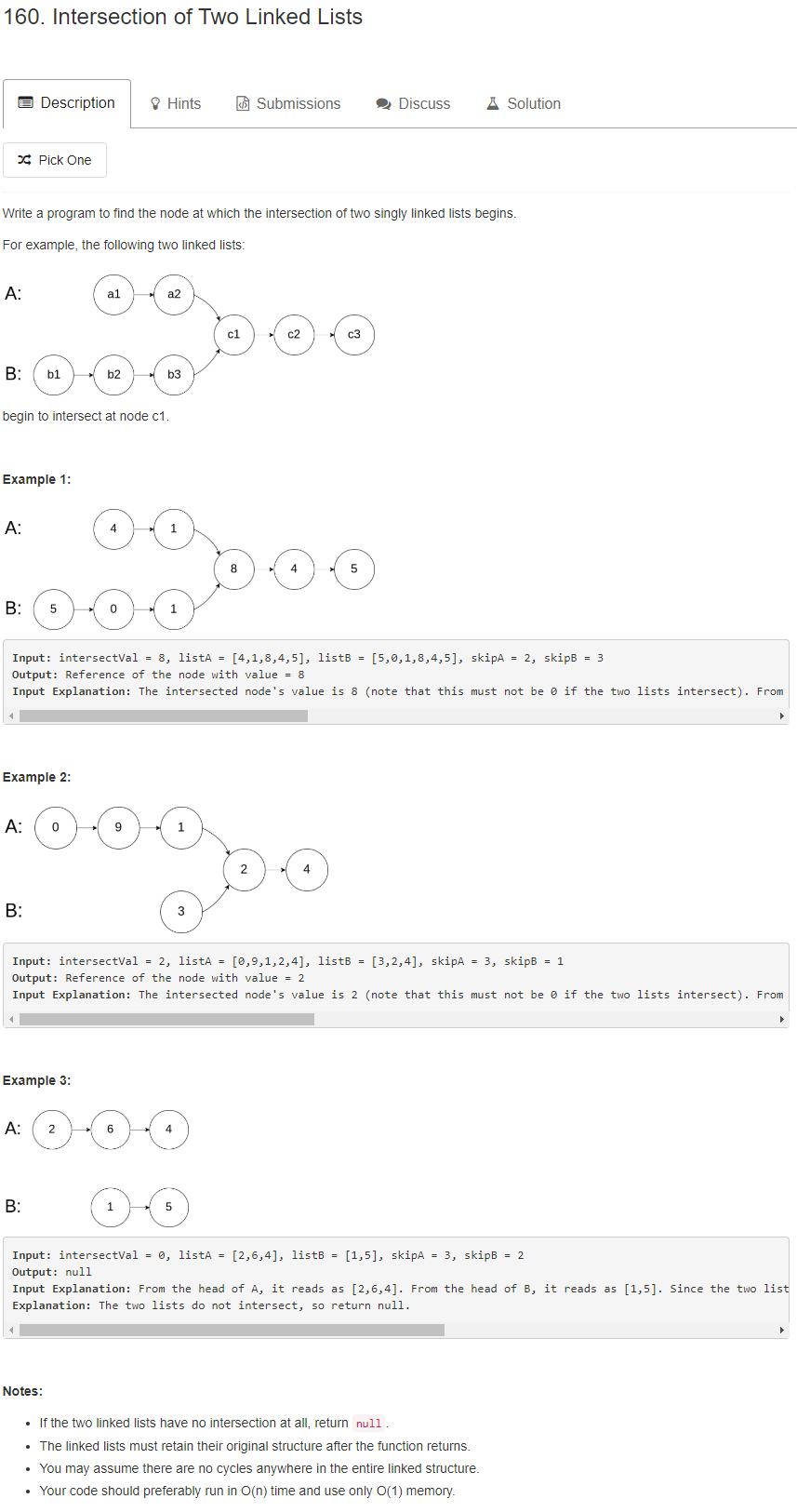
两个链表,如果有重合的部分,把相遇点返回。如果没有重合的部分,就返回 null。
思路分析
最暴力的方法就是选择链表 A 的每个节点,然后考虑链表 B 能否到达,但时间复杂度会达到 O(mn) 。
再进行优化的话,可以利用一个 HashMap,将链表 A 中所有的节点存入,然后遍历链表 B 的每一个节点,看 HashMap 中是否存在即可。时间复杂度优化到了 O(n),但同时需要 O(n) 的空间。
接下来我们只考虑时间复杂度 O(n),空间复杂度为 O(1) 的解法。
解法一
有一些 142 题(找出链表环的入口点)解法的影子。我们需要两个指针,分别从两个链表的某个位置开始遍历,当两个指针相遇的时候,刚好停在两个链表的相遇点问题也就解决了。
所以最关键的问题就是从链表的某个位置开始遍历,那么从哪个位置呢?
如果把问题简单化,假如两个链表有重合部分,并且两个链表的总长度相等。那么我们只需要让两个指针分别从链表头遍历即可,也就是下边的例子,指针 A 从 1 开始遍历,指针 B 从 4 同时遍历,那么两个指针就会在 7 相遇,就是我们要找的位置。
1 -> 2 -> 3
-> 7 -> 8 -> 9
4 -> 5 -> 6
如果两个链表长度不相等呢,比如下边的例子。
1 -> 2 -> 3
-> 7 -> 8 -> 9
4 -> 5 -> 6 -> 7 -> 8
此时短的链表还是从链表头 1 开始,但是长的链表就应该先多走 2步,从 6 开始。
为什么多走 2 步呢?很简单,因为没有重合的链表部分 1 2 3 和 4 5 6 7 8,长度差了 2。怎么算出这个长度呢?我们只需要用两个链表的总长度做差即可(原因:重合部分相减为 0 ,最终结果就相当于不重合部分的差),也就是 8 - 6 = 2 。
综上,我们只需要算出两个链表的长度,让长的的链表提前走几步,然后再同时开始遍历,相遇点就是我们要找的位置。
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
if (headA == null || headB == null) {
return null;
}
ListNode tailA = headA;
int lenA = 0;
//链表 A 的长度
while (tailA.next != null) {
tailA = tailA.next;
lenA++;
}
ListNode tailB = headB;
int lenB = 0;
//链表 B 的长度
while (tailB.next != null) {
tailB = tailB.next;
lenB++;
}
//没有重合部分,直接结束
if (tailA != tailB) {
return null;
}
//让长的链表提前走
if (lenA > lenB) {
int sub = lenA - lenB;
while (sub > 0) {
headA = headA.next;
sub--;
}
} else {
int sub = lenB - lenA;
while (sub > 0) {
headB = headB.next;
sub--;
}
}
//依次遍历,找到相遇点
while (headA != headB) {
headA = headA.next;
headB = headB.next;
}
return headA;
}
这里 看到另一种写法,但本质上和上边是一样的,分享一下。
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
if(headA == null || headB == null) return null;
ListNode a = headA;
ListNode b = headB;
while( a != b){
a = a == null? headB : a.next;
b = b == null? headA : b.next;
}
return a;
}
上边的代码简洁了很多,它没有去分别求两个链表的长度,而是把所有的情况都合并了起来。
如果没有重合部分,那么
a和b在某一时间点 一定会同时走到null,从而结束循环。如果有重合部分,分两种情况。
- 长度相同的话,
a和b一定是同时到达相遇点,然后返回。 - 长度不同的话,较短的链表先到达结尾,然后指针转向较长的链表。此刻,较长的链表继续向末尾走,多走的距离刚好就是最开始介绍的解法,链表的长度差,走完之后指针转向较短的链表。然后继续走的话,相遇的位置就刚好是相遇点了。
- 长度相同的话,
综上,代码巧妙的把所有情况合并了起来。
解法二
最开始考虑这道题的时候,我还想了另一种思路。就是遍历某一个链表,把这个链表的每个节点进行标记,这里的话当然就是对 val 进行特殊标记。然后再遍历另一个链表,发现了这个标记也就找到了相遇点了。当然,这个标记一定得是可逆的,完成任务后我们要把原来链表的 val 进行还原。
常用的标记方法,比如取它相反数,取绝对值,异或,找一个不可能存在的数赋值过去等等,但对于这道题都无效。然后自己到这里思路也就断了,后来就想到了上边的解法一。
这里-time-and-O(1)-memory-(72ms)) 看到了类似于标记的方法,蛮有意思,分享一下,分下边几步。
- 统计链表
A的所有节点val的和,记为sumA,同时记录长度lenA。 - 把链表
B的所有节点的val都进行加1。 - 再次统计链表
A的所有节点val的和,记为sumA2。 - 将链表
B的所有节点的val都进行减1,相当于还原。
有了上边的几个数据就可以知道。
sumA == sumA2的话,就表明两个链表没有重合部分。sumA != sumA2的话,sub = sumA2 - sumA,由于我们对重合部分的val进行了加1,所以前后的差sub就刚好表示了重合节点的个数。同时我们知道链表 A 的总长度lenA,所以我们只需要对链表 A 遍历lenA - sub次,就刚好会走到重合部分的开头了,也就是我们要找的相遇点。
代码如下。
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
if (headA == null || headB == null) {
return null;
}
//步骤 1
ListNode tailA = headA;
int lenA = 0;
int sumA = 0;
while (tailA != null) {
sumA += tailA.val;
tailA = tailA.next;
lenA++;
}
//步骤 2
ListNode tailB = headB;
while (tailB != null) {
tailB.val = tailB.val + 1;
tailB = tailB.next;
}
//步骤 3
tailA = headA;
int sumA2 = 0;
while (tailA != null) {
sumA2 += tailA.val;
tailA = tailA.next;
}
//步骤 4
tailB = headB;
while (tailB != null) {
tailB.val = tailB.val - 1;
tailB = tailB.next;
}
if (sumA == sumA2) {
return null;
} else {
for (int i = 0; i < lenA - (sumA2 - sumA); i++) {
headA = headA.next;
}
return headA;
}
}
上边算法的缺点就是,由于进行了加 1 操作,对于过大的数可能会引起溢出,此外求和也很有可能引起溢出。但思想还是很有趣的。
总
遇到题以后,可以对不同的情况分析,回想之前的一些思想,从而找到突破口。