题目描述(中等难度)
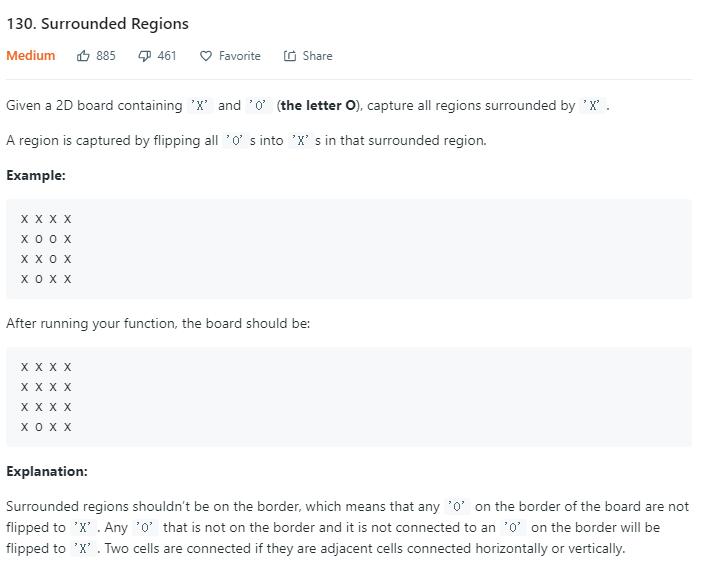
有一点点像围棋,把被 X 围起来的 O 变成 X,边界的 O 一定不会被围起来。如果 O 和边界的 O 连通起来,那么这些 O 就都算作不被围起来,比如下边的例子。
X X X X X
O O O X X
X X X O X
X O X X X
上边的例子就只需要变化 1 个 O 。
X X X X X
O O O X X
X X X X X
X O X X X
解法一
把相邻的O 看作是连通的图,然后从每一个 O 开始做 DFS。
如果遍历完成后没有到达边界的 O ,我们就把当前 O 改成 X。
如果遍历过程中到达了边界的 O ,直接结束 DFS,当前的 O 就不用操作。
然后继续考虑下一个 O,继续做一次 DFS。
public void solve(char[][] board) {
int rows = board.length;
if (rows == 0) {
return;
}
int cols = board[0].length;
//考虑除去边界以外的所有 O
for (int i = 1; i < rows - 1; i++) {
for (int j = 1; j < cols - 1; j++) {
if (board[i][j] == 'O') {
//visited 用于记录 DFS 过程中已经访问过的节点
HashSet<String> visited = new HashSet<>();
//如果没有到达边界,就把当前 O 置为 X
if (!solveHelper(i, j, board, visited)) {
board[i][j] = 'X';
}
}
}
}
}
private boolean solveHelper(int row, int col, char[][] board, HashSet<String> visited) {
//是否访问过
if (visited.contains(row + "@" + col)) {
return false;
}
visited.add(row + "@" + col);
//到达了 X 直接返回 false
if (board[row][col] == 'X') {
return false;
}
if (row == 0 || row == board.length - 1 || col == 0 || col == board[0].length - 1) {
return true;
}
//分别尝试四个方向
if (solveHelper(row - 1, col, board, visited)
|| solveHelper(row, col - 1, board, visited)
|| solveHelper(row + 1, col, board, visited)
|| solveHelper(row, col + 1, board, visited)) {
return true;
} else {
return false;
}
}
遗憾的是,到最后两个 test 的时候超时了。

优化的的话,我尝试了在每次 DFS 过程中,返回 true 之前,把当前的 row 和 col 记录下来,然后第二次遇到这些点的时候,就直接跳过 。
public void solve(char[][] board) {
int rows = board.length;
if (rows == 0) {
return;
}
//记录可以连通到边界的 O
HashSet<String> memoization = new HashSet<>();
int cols = board[0].length;
for (int i = 1; i < rows - 1; i++) {
for (int j = 1; j < cols - 1; j++) {
if (board[i][j] == 'O') {
//如果当前位置的 O 被记录过了,直接跳过
if (memoization.contains(i + "@" + j)) {
continue;
}
HashSet<String> visited = new HashSet<>();
if (!solveHelper(i, j, board, visited, memoization)) {
board[i][j] = 'X';
}
}
}
}
}
private boolean solveHelper(int row, int col, char[][] board, HashSet<String> visited,
HashSet<String> memoization) {
if (visited.contains(row + "@" + col)) {
return false;
}
visited.add(row + "@" + col);
if (board[row][col] == 'X') {
return false;
}
//当前位置可以连通到边界,返回 true
if (memoization.contains(row + "@" +col)) {
return true;
}
if (row == 0 || row == board.length - 1 || col == 0 || col == board[0].length - 1) {
//当前位置可以连通道边界,记录下来
memoization.add(row + "@" + col);
return true;
}
if (solveHelper(row - 1, col, board, visited, memoization)
|| solveHelper(row, col - 1, board, visited, memoization)
|| solveHelper(row + 1, col, board, visited, memoization)
|| solveHelper(row, col + 1, board, visited, memoization)) {
//当前位置可以连通道边界,记录下来
memoization.add(row + "@" + col);
return true;
} else {
return false;
}
}
但没什么效果,依旧还是超时。
之前还考虑过能不能在遍历过程中,返回 false 之前,直接把 O 改成 X。最后发现是不可以的,比如下边的例子。
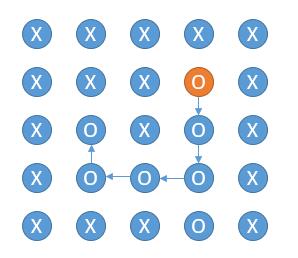
如果我们从橙色的 O 做 DFS,然后沿着箭头方向,到达最后一个 O 的时候,它的左边上边右边都是 X ,根据代码它就返回 false,此外它下边是访问过的节点也会返回 false,所以四个方向都返回 false,如果把它改成 X明显是不对的。
解法二
解法一是从当前节点做 DFS ,然后看它是否能到达边界的 O。那么我们能不能把思路逆转过来呢?
从边界的 O 做 DFS,然后把遇到的 O 都标记一下,这些 O 就是可以连通到边界的。然后把边界的所有的 O 都做一次 DFS ,把 DFS 过程的中的 O 做一下标记。最后我们只需要遍历节点,把没有标记过的 O 改成 X 就可以了。
标记的话,我们可以用一个 visited 二维数组,把访问过的置为 true 。
public void solve(char[][] board) {
int rows = board.length;
if (rows == 0) {
return;
}
int cols = board[0].length;
boolean[][] visited = new boolean[rows][cols];
for (int i = 0; i < cols; i++) {
//最上边一行的所有 O 做 DFS
if (board[0][i] == 'O') {
dfs(0, i, board, visited);
}
//最下边一行的所有 O 做 DFS
if (board[board.length - 1][i] == 'O') {
dfs(board.length - 1, i, board, visited);
}
}
for (int i = 1; i < rows - 1; i++) {
//最左边一列的所有 O 做 DFS
if (board[i][0] == 'O') {
dfs(i, 0, board, visited);
}
//最右边一列的所有 O 做 DFS
if (board[i][board[0].length - 1] == 'O') {
dfs(i, board[0].length - 1, board, visited);
}
}
//把所有没有标记过的 O 改为 X
for (int i = 0; i < rows; i++) {
for (int j = 0; j < cols; j++) {
//省略了对 X 的判断,把 X 变成 X 不影响结果
if (!visited[i][j]) {
board[i][j] = 'X';
}
}
}
}
private void dfs(int i, int j, char[][] board, boolean[][] visited) {
if (i < 0 || j < 0 || i == board.length || j == board[0].length) {
return;
}
if (visited[i][j]) {
return;
}
if (board[i][j] == 'O') {
visited[i][j] = true;
dfs(i + 1, j, board, visited);
dfs(i, j + 1, board, visited);
dfs(i, j - 1, board, visited);
dfs(i - 1, j, board, visited);
}
}
然后这个解法 AC 了,但空间复杂度可以优化一下,这个思想很多题用过了,比如 79 题。
这里的 visited 的二维数组我们可以不需要。我们可以先把连通的 O 改成 *,或者其他的字符。最后遍历整个 board,遇到 * 就把它还原到 O 。遇到 O,因为它没有被修改成*,也就意味着它没有连到边界,就把它改成 X。
public void solve(char[][] board) {
int rows = board.length;
if (rows == 0) {
return;
}
int cols = board[0].length;
for (int i = 0; i < cols; i++) {
//最上边一行的所有 O 做 DFS
if (board[0][i] == 'O') {
dfs(0, i, board);
}
//最下边一行的所有 O 做 DFS
if (board[board.length - 1][i] == 'O') {
dfs(board.length - 1, i, board);
}
}
for (int i = 1; i < rows - 1; i++) {
//最左边一列的所有 O 做 DFS
if (board[i][0] == 'O') {
dfs(i, 0, board);
}
//最右边一列的所有 O 做 DFS
if (board[i][board[0].length - 1] == 'O') {
dfs(i, board[0].length - 1, board);
}
}
//把所有没有标记过的 O 改为 X,标记过的还原
for (int i = 0; i < rows; i++) {
for (int j = 0; j < cols; j++) {
if (board[i][j] == '*') {
board[i][j] = 'O';
}else if(board[i][j] == 'O'){
board[i][j] = 'X';
}
}
}
}
private void dfs(int i, int j, char[][] board) {
if (i < 0 || j < 0 || i == board.length || j == board[0].length) {
return;
}
if (board[i][j] == '*') {
return;
}
if (board[i][j] == 'O') {
board[i][j] = '*';
dfs(i + 1, j, board);
dfs(i, j + 1, board);
dfs(i, j - 1, board);
dfs(i - 1, j, board);
}
}
但是在逛 Disscuss 的时候发现有人提出来说,DFS 的解法可能导致栈溢出。
这个 解法 下的第一个评论,我把原文贴过来。
This is a DFS solution, but it may causes a stack overflow issue.
When you use DFS, it is tricky to use:
if(i>1) check(vec,i-1,j,row,col); if(j>1) check(vec,i,j-1,row,col);because it is more common to write like this:
if(i>=1) check(vec,i-1,j,row,col); if(j>=1) check(vec,i,j-1,row,col);Then I'll explain it.
There is a test case like this:
OOOOOOOOOO XXXXXXXXXO OOOOOOOOOO OXXXXXXXXX OOOOOOOOOO XXXXXXXXXO OOOOOOOOOO OXXXXXXXXX OOOOOOOOOO XXXXXXXXXOTo make it clear, I draw a 10x10 board, but it is actually a 250x250 board like this one.
When dfs function visit
board[0][0], it ought to visit every grid marked 'O', thus lead to stack overflow(runtime error).After you change "if(j>=1)" to "if(j>1)", the DFS function won't check
board[i][0](0<=i<=row-1), and then not all the grids marked 'O' will be visited when you dfs(board[0][0]). Your code won't cause stack overflow in this test case, but if we change the test case a little, it won't work well.Consider a test case like this:
OOOOOOOOOOOX XXXXXXXXXXOX XOOOOOOOOOOX XOXXXXXXXXXX XOOOOOOOOOOX XXXXXXXXXXOX XOOOOOOOOOOX XOXXXXXXXXXX XOOOOOOOOOOX XXXXXXXXXXOXI draw a 10x12 board, but it may be as large as the 250x250 board.
I believe that your code will get "runtime error" in this test case when tested in Leetcode system.
他的意思就是说,比如下边的例子类型,假如是 250 × 250 大小的话,因为我们做的是 DFS,一直压栈的话就会造成溢出。
OOOOOOOOOOOX
XXXXXXXXXXOX
XOOOOOOOOOOX
XOXXXXXXXXXX
XOOOOOOOOOOX
XXXXXXXXXXOX
XOOOOOOOOOOX
XOXXXXXXXXXX
XOOOOOOOOOOX
XXXXXXXXXXOX
但是我的代码已经通过了呀,一个可能的原因就是 leetcode 升级了,因为这是 2015 年的评论,现在是 2019 年,压栈的大小足够大了,只要有递归出口,就不用担心压栈放不下了。我就好奇的想测一下 leetcode 的压栈到底有多大。写了一个简单的递归代码。
public void solve(char[][] board) {
dfs(2677574);
}
private int dfs(int count) {
if (count == 0) {
return 1;
}
return dfs(count - 1);
}
然后一开始传一个较大的数字,然后利用二分法,开始不停试探那个溢出的临界点是多少。经过多次尝试,发现 2677574 的话就会造成溢出。2677573 就不会造成溢出。本以为这样就结束了,然后准备截图总结的时候发现。取 2677574 竟然不溢出了,2677573 反而溢出了。
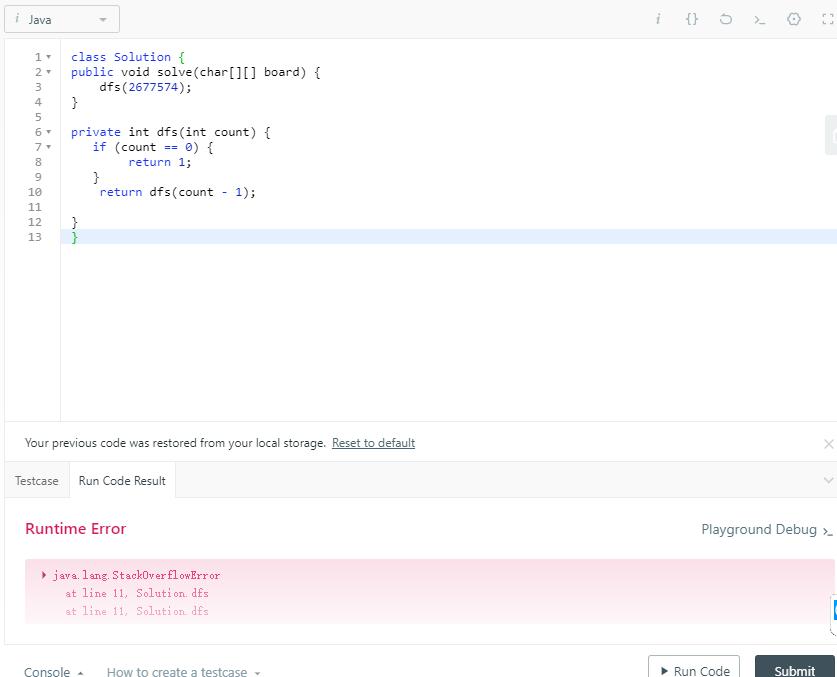
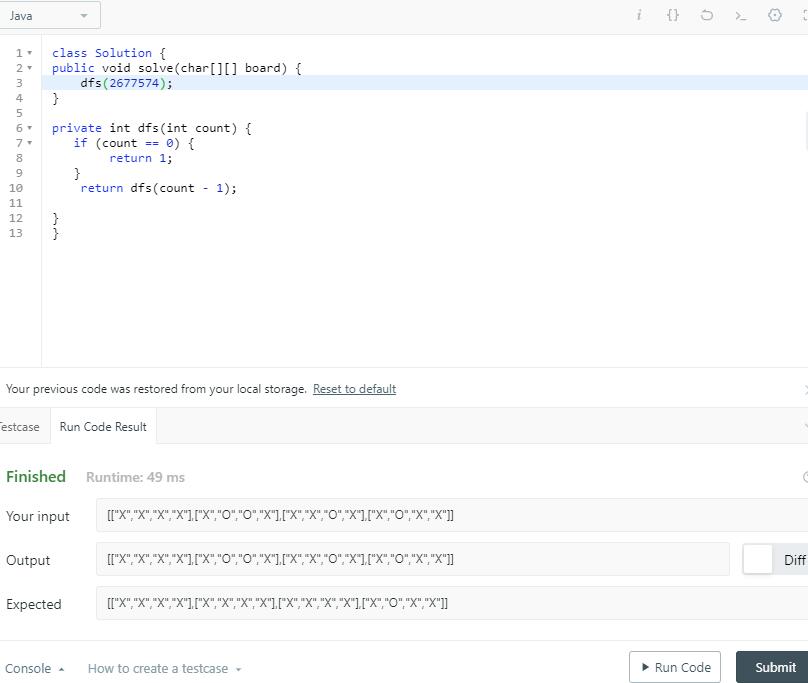
同一个数字,一会儿溢出一会儿不溢出,那就没办法得出结论了。那可能栈的大小和它服务器当前的承载的能力有关了,不过一般情况的栈的大小肯定足够解决题目了。
那么退一步讲,如果它的栈的限定很小,这里的 DFS 行不通,我们有什么解决方案吗?
这里我想到两种,一种就是用栈去模拟递归,这里的栈当然就是对象了,存在堆里,就不用担心函数栈溢出了。
另一种,利用一个队列,去实现 BFS,首先把四个边界的 O 加到队列中,然后按照正常的 BFS 和之前一样访问连通的 O 并且进行标记。最后再把没有标记的 O 改成 X 就可以了。
解法三
这里再介绍另外一种思想,参考 这里,就是并查集,其实本质上和上边的解法是一样的,只是抽象出了一种数据结构,在很多地方都有应用。
看下维基百科对 并查集 的定义。
在计算机科学中,并查集是一种树型的数据结构,用于处理一些不交集(Disjoint Sets)的合并及查询问题。有一个联合-查找算法(union-find algorithm)定义了两个用于此数据结构的操作:
- Find:确定元素属于哪一个子集。它可以被用来确定两个元素是否属于同一子集。
- Union:将两个子集合并成同一个集合。
由于支持这两种操作,一个不相交集也常被称为联合-查找数据结构(union-find data structure)或合并-查找集合(merge-find set)。其他的重要方法,MakeSet,用于创建单元素集合。有了这些方法,许多经典的划分问题可以被解决。
为了更加精确的定义这些方法,需要定义如何表示集合。一种常用的策略是为每个集合选定一个固定的元素,称为代表,以表示整个集合。接着,Find(x) 返回 x 所属集合的代表,而 Union 使用两个集合的代表作为参数。
网上很多讲并查集的文章了,这里推荐 一篇。
知道了并查集,下边就很好解决了,因为你会发现,我们做的就是分类的问题,O 其实最终就是两大类,一种能连通到边界,一种不能连通到边界。
首先我们把每个节点各作为一类,用它的行数和列数生成一个 id 标识该类。
int node(int i, int j) {
return i * cols + j;
}
然后遍历每个 O节点,和它上下左右的节点进行合并即可。
如果当前节点是边界的 O,就把它和 dummy 节点(一个在所有节点外的节点)合并。最后就会把所有连通到边界的 o 节点和 dummy 节点合为了一类。
最后我们只需要判断,每一个 o 节点是否和 dummy 节点是不是一类即可。
public class Solution {
int rows, cols;
public void solve(char[][] board) {
if(board == null || board.length == 0) return;
rows = board.length;
cols = board[0].length;
//多申请一个空间
UnionFind uf = new UnionFind(rows * cols + 1);
//所有边界的 O 节点都和 dummy 节点合并
int dummyNode = rows * cols;
for(int i = 0; i < rows; i++) {
for(int j = 0; j < cols; j++) {
if(board[i][j] == 'O') {
//当前节点在边界就和 dummy 合并
if(i == 0 || i == rows-1 || j == 0 || j == cols-1) {
uf.union( dummyNode,node(i,j));
}
else {
//将上下左右的 O 节点和当前节点合并
if(board[i-1][j] == 'O') uf.union(node(i,j), node(i-1,j));
if(board[i+1][j] == 'O') uf.union(node(i,j), node(i+1,j));
if(board[i][j-1] == 'O') uf.union(node(i,j), node(i, j-1));
if( board[i][j+1] == 'O') uf.union(node(i,j), node(i, j+1));
}
}
}
}
for(int i = 0; i < rows; i++) {
for(int j = 0; j < cols; j++) {
//判断是否和 dummy 节点是一类
if(uf.isConnected(node(i,j), dummyNode)) {
board[i][j] = 'O';
}
else {
board[i][j] = 'X';
}
}
}
}
int node(int i, int j) {
return i * cols + j;
}
}
class UnionFind {
int [] parents;
public UnionFind(int totalNodes) {
parents = new int[totalNodes];
for(int i = 0; i < totalNodes; i++) {
parents[i] = i;
}
}
void union(int node1, int node2) {
int root1 = find(node1);
int root2 = find(node2);
if(root1 != root2) {
parents[root2] = root1;
}
}
int find(int node) {
while(parents[node] != node) {
parents[node] = parents[parents[node]];
node = parents[node];
}
return node;
}
boolean isConnected(int node1, int node2) {
return find(node1) == find(node2);
}
}
总
解法一到解法二仅仅是思路的一个逆转,速度却带来了质的提升。所以有时候走到了死胡同,可以试试往回走。
刷这么多题第一次应用到了并查集,并查集说简单点,就是每一类选一个代表,然后类中的其他元素最终都可以找到这个代表。然后遍历其他元素,将它合并到某个类中。